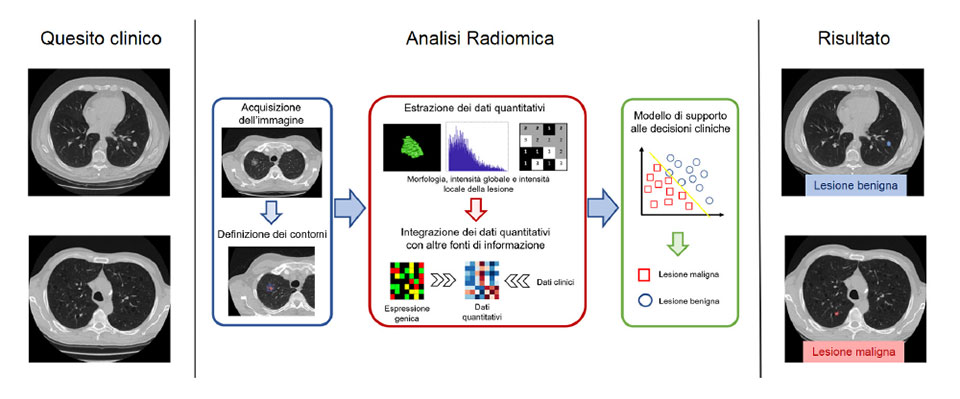
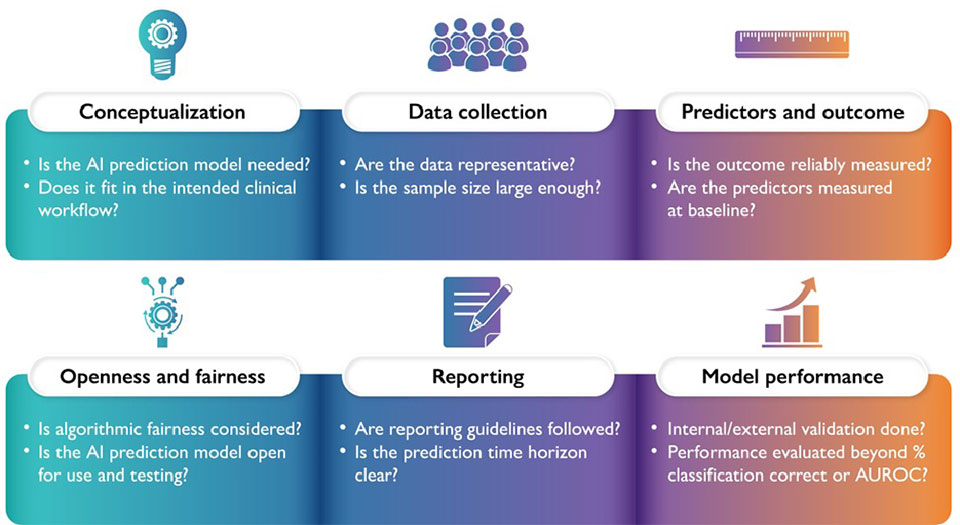
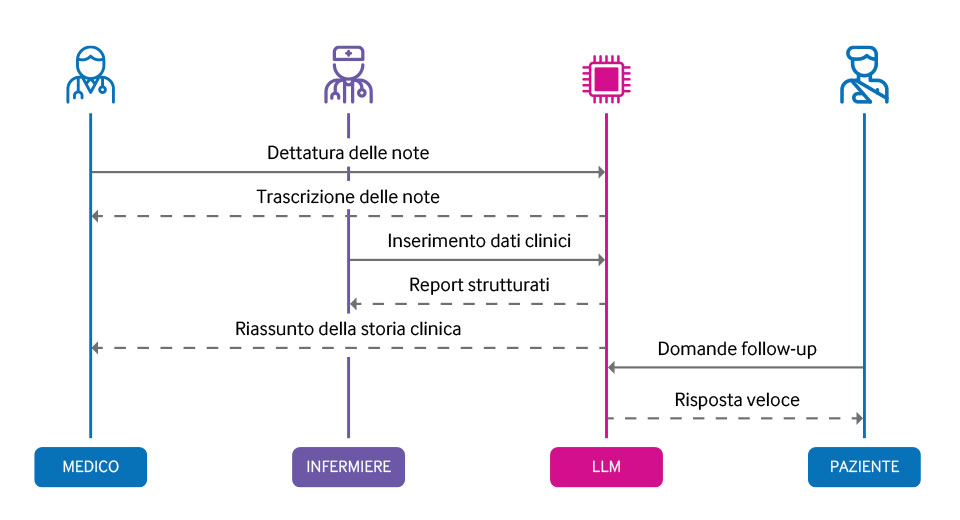
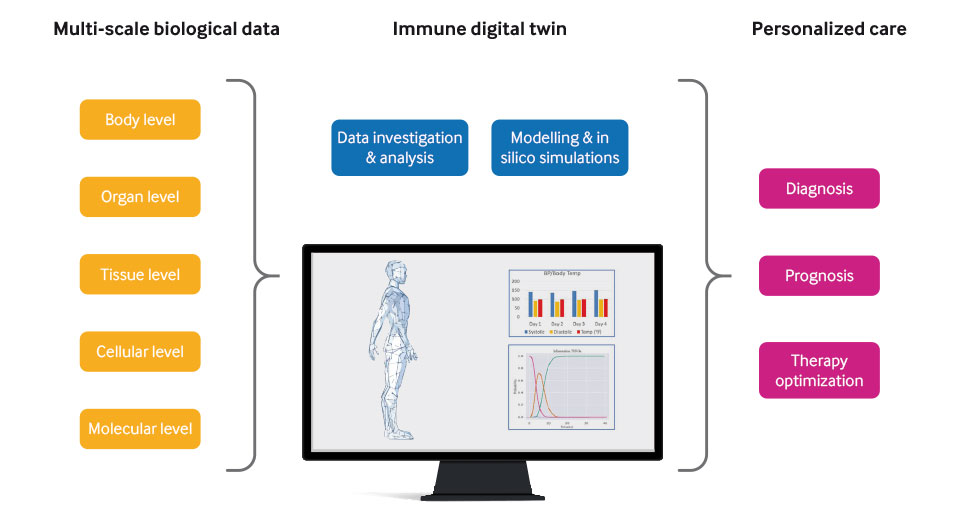
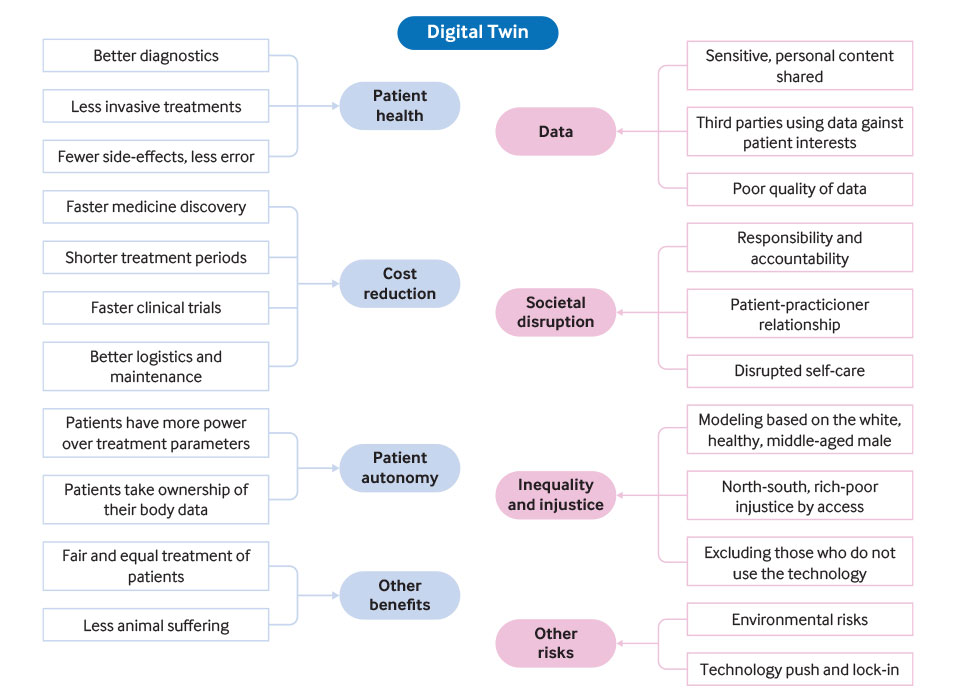
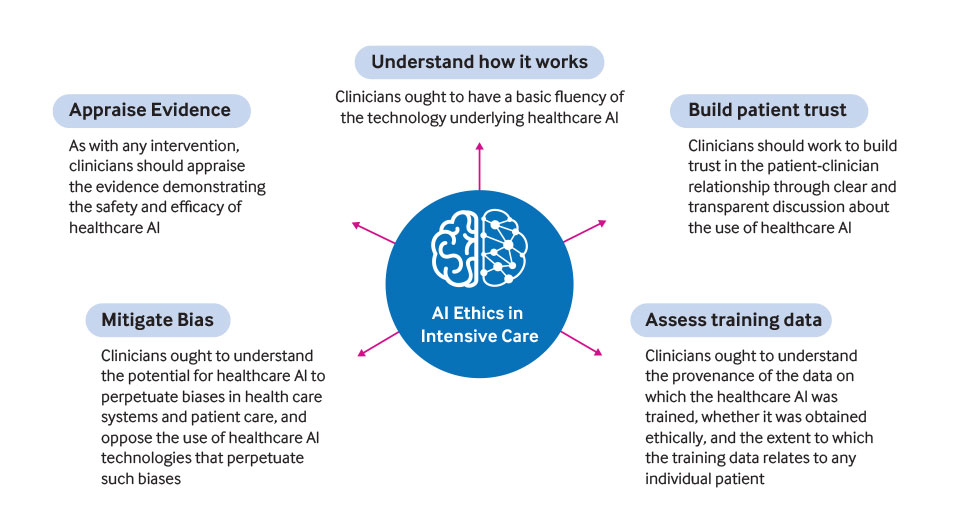
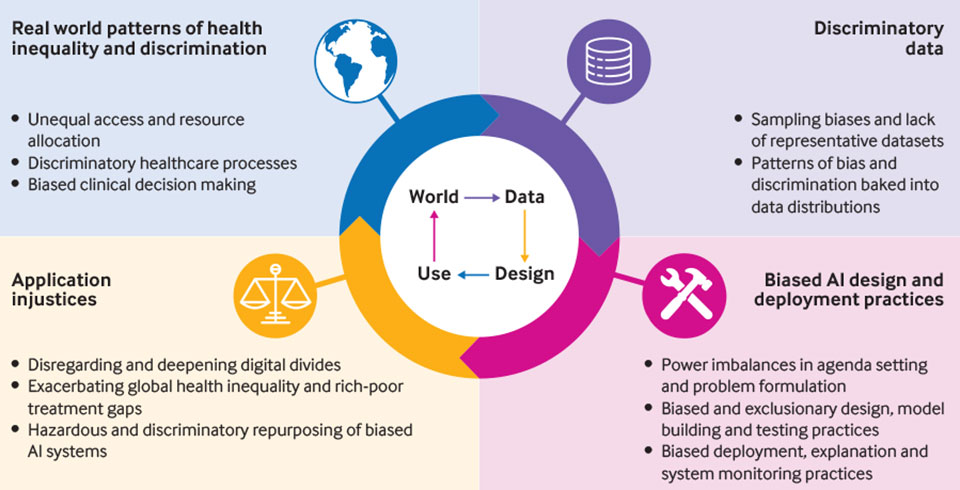
L’Intelligenza Artificiale (AI) vede i propri albori alla metà del secolo scorso.
Nel 1950 Alan Turing, matematico britannico, ipotizza per la prima volta la plausibilità di una macchina pensante, ma la nascita vera e propria dell’AI viene fatta risalire al 1956, al Dartmouth College, nel New Hampshire, dove si riunirono in un convegno i principali esperti di informatica dell’epoca, con lo scopo di creare una macchina in grado di simulare i processi di apprendimento del cervello umano. Fu proprio uno degli organizzatori del congresso, John McCarthy, a creare il termine Intelligenza Artificiale. Le sfide che i ricercatori si trovavano affrontare consistevano sostanzialmente nella creazione di sistemi che potessero risolvere problemi in maniera efficiente, e in grado di apprendere autonomamente.
Esistono varie definizioni di AI. Quella recentemente adottata dalla Comunità Europea è la seguente:
Artificial intelligence (AI) refers to systems that display intelligent behaviour by analysing their environment and taking actions – with some degree of autonomy – to achieve specific goals.
Sempre la Comunità Europea caratterizza ulteriormente la descrizione dell’AI descrivendone altre proprietà:
“L’intelligenza artificiale è l’abilità di una macchina di mostrare capacità umane quali il ragionamento, l’apprendimento, la pianificazione e la creatività. I sistemi di IA sono capaci di adattare il proprio comportamento analizzando gli effetti delle azioni precedenti e lavorando in autonomia”.
I sistemi di IA possono essere addestrati per eseguire una vasta gamma di compiti e adattarsi a condizioni in continua evoluzione.
Molte delle esperienze tecnologiche della nostra quotidianità vedono alla propria base un sistema di intelligenza artificiale. Di seguito si riportano alcuni esempi.
I filtri spam di molti provider di posta elettronica, in particolare di Gmail, sono basati su sistemi di interpretazione del linguaggio naturale che permettono di intercettare con una buona efficacia eventuali email indesiderate. Un’altra funzione di Gmail, lo Smart Compose, tramite un’analisi del contesto, permette di suggerire parole e frasi mentre l’utente digita l’oggetto e il contenuto dell’email. Anche questa funzione è basata su tecniche avanzate di Natural Language Processing (NLP).
Anche molte funzioni di Google Maps sono basate su AI. Un modo in cui l’AI viene utilizzata in Google Maps è per migliorare l’accuratezza delle mappe stesse. Per esempio, gli algoritmi di AI possono analizzare immagini satellitari e foto a livello di strada per identificare e etichettare caratteristiche come edifici, strade e punti di riferimento. Ciò può contribuire a garantire che le mappe siano aggiornate e accurate e che riflettano l’ambiente reale. L’AI viene anche utilizzata per migliorare le funzionalità di Google Maps. Per esempio, l’app può utilizzare algoritmi di machine learning per prevedere i modelli di traffico e suggerire i migliori percorsi per gli utenti in base alle condizioni del traffico attuali. Può anche utilizzare l’AI per fornire raccomandazioni personalizzate per luoghi da visitare e cose da fare in base alla posizione dell’utente e alla cronologia delle ricerche.
Facebook ha una funzione che utilizza l’intelligenza artificiale per rilevare e gestire i post di utenti che potrebbero essere a rischio di suicidio. La funzione si basa su un algoritmo di machine learning che analizza i post degli utenti alla ricerca di parole chiave e frasi che potrebbero indicare un rischio di suicidio. Se il sistema rileva un post che potrebbe essere a rischio, viene inviato un avviso a un team di esperti in salute mentale che valuta il post e, se necessario, contatta l’utente per offrire supporto e consigli.
Molte piattaforme, tra cui Amazon, Netflix e Spotify, utilizzano sofisticati sistemi di AI, in particolare il Deep Learning, per analizzare il comportamento di ascolto dei suoi utenti e fornire loro raccomandazioni personalizzate di prodotti da acquistare, serie TV, brani e playlist che potrebbero essere di loro interesse. Tramite questi algoritmi, le piattaforme analizzano i dati di acquisto/visione/ascolto degli utenti per comprendere quali elementi (articoli, venditori, generi di film, attori, trame, generi musicali, artisti, album) tendono a essere più apprezzati. Per fornire raccomandazioni personalizzate, vengono usati anche i feedback e le valutazioni degli utenti. Per esempio, su Spotify, se un utente dà una valutazione positiva a un brano o aggiunge un brano a una playlist personale, il sistema potrebbe utilizzare questa informazione per suggerire altri brani simili a utenti con caratteristiche simili.
Encore, che prima si chiamava Shazam, è un’applicazione che permette di comprendere quale brano musicale si sta ascoltando registrandone pochi secondi. L’applicazione utilizza algoritmi di machine learning che sono stati addestrati su un gran numero di esempi di segnali audio e di metadati associati a questi elementi audio. Grazie a questo addestramento, gli algoritmi di Shazam sono in grado di riconoscere caratteristiche specifiche del segnale audio che sono tipiche di un brano musicale o di un altro elemento audio, e quindi di individuare le corrispondenze con gli elementi presenti nel suo database.
Anche gli assistenti virtuali degli smartphone, per esempio Siri o Google Assistant, sono basati sull’intelligenza artificiale. Utilizzano tecnologie di elaborazione del linguaggio naturale, machine learning e altre tecniche di intelligenza artificiale per comprendere e rispondere alle richieste degli utenti in modo naturale, utilizzando la voce.
Le funzioni di riconoscimento facciale degli smartphone utilizzano la fotocamera del dispositivo per acquisire un’immagine o un video della faccia dell’utente e utilizzano tecniche di intelligenza artificiale, in particolare l’apprendimento automatico, per analizzare queste immagini e riconoscere i tratti distintivi della faccia dell’utente. Per fare ciò, le funzioni di riconoscimento facciale utilizzano algoritmi di machine learning che sono stati addestrati su un gran numero di immagini di volti umani e sui metadati associati a queste immagini. Grazie a questo addestramento, gli algoritmi sono in grado di riconoscere tratti distintivi come il contorno del viso, la posizione degli occhi, del naso e della bocca, e le distanze tra questi elementi. In questo modo, le funzioni di riconoscimento facciale possono determinare con una certa precisione se una persona presente nell’immagine è l’utente del dispositivo o un’altra persona. Una volta che la faccia dell’utente viene riconosciuta, il dispositivo può sbloccarsi o eseguire altre azioni specifiche impostate dall’utente.
Moltissime funzioni della guida degli aerei sono basate sull’intelligenza artificiale, che in questo caso agisce a supporto del lavoro dei piloti. Per esempio, alcuni sistemi di volo utilizzano l’intelligenza artificiale per raccogliere e analizzare dati in tempo reale da diversi sensori a bordo dell’aereo e fornire informazioni utili ai piloti, come avvisi di collisione o di condizioni meteorologiche avverse. Inoltre, alcuni sistemi di navigazione aerea utilizzano l’intelligenza artificiale per ottimizzare i percorsi di volo in base a diverse variabili, come il traffico aereo, le condizioni meteorologiche e i requisiti di carburante.
Infine, le Tesla che sono dotate di guida autonoma utilizzano diverse tecnologie di intelligenza artificiale per rilevare e interpretare gli elementi del loro ambiente circostante e prendere decisioni su come muoversi. Queste tecnologie includono sensori a ultrasuoni, radar e telecamere a bordo del veicolo, che vengono utilizzati per raccogliere dati sulla strada, gli altri veicoli, i pedoni e altri elementi presenti nel loro ambiente di guida. Inoltre, le Tesla utilizzano algoritmi di machine learning basati sui dati raccolti da questi sensori per identificare modelli e tendenze nel traffico e prendere decisioni sulla base di queste informazioni. Per esempio, gli algoritmi possono utilizzare i dati sulla posizione e la velocità degli altri veicoli per determinare il momento migliore per cambiare corsia o per prendere un’uscita, o per evitare ostacoli imprevisti come pedoni che attraversano la strada.
Per orientarci meglio nelle prossime lezioni, è bene chiarire qual è la differenza tra i concetti di Intelligenza Artificiale, Machine Learning e Deep
Learning. Per comprendere come si relazionano tra di loro questi ambiti, è spesso utilizzata la metafora della matrioska.
- Con il termine Intelligenza Artificiale, ci riferiamo a sistemi in grado di realizzare compiti che normalmente richiedono intelligenza umana.
- Il Machine Learning è una branca dell’AI, che si riferisce invece a sistemi in grado di imparare senza essere esplicitamente programmati. Il sistema impara dai dati utilizzando tecniche di natura statistica, dalla regressione lineare a tecniche molto più complesse, come, appunto, il Deep Learning. L’apprendimento da parte di algoritmi di Machine Learning può essere supervisionato o non supervisionato. Nell’apprendimento supervisionato viene fornito all’algoritmo un insieme di dati di training, che includono esempi di input e il rispettivo output desiderato (ovvero dati classificati, per esempio immagini di frutta e il nome della frutta rappresentata in ciascuna immagine). L’algoritmo utilizza questi dati per “imparare” ad associare gli input agli output desiderati (ovvero, per esempio, classificare l’immagine di una mela come mela). Una volta che l’algoritmo è stato addestrato, può essere testato su un nuovo insieme di dati, noto come set di test (anche in questo caso si tratta di dati già classificati), per vedere come si comporta su nuovi input. L’apprendimento non supervisionato è una forma di apprendimento automatizzato in cui un algoritmo di machine learning viene addestrato su un insieme di dati senza alcun output etichettato. L’obiettivo è quello di far sì che l’algoritmo scopra automaticamente le strutture e le relazioni presenti nei dati. In genere, l’apprendimento non supervisionato viene utilizzato per esplorare i dati e scoprire eventuali pattern o relazioni nascoste.
- Il Deep Learning si basa su una struttura logica molto simile a quella del cervello umano: gli artificial neural network. Negli artificial neural network, abbiamo uno strato di input, rappresentato dai dati in entrata, uno strato di output, rappresentato dai dati in uscita, e degli strati intermedi, i cosiddetti strati nascosti. Più strati nascosti ci sono, più profonda (deep) è la rete. Ogni strato della rete neurale profonda può essere considerato come una rappresentazione sempre più complessa e raffinata dei dati, dove ciascuno strato successivo estrae informazioni più dettagliate e specifiche dai dati di ingresso.
La differenza tra gli algoritmi di Deep Learning e gli algoritmi di Machine Learning tradizionali, è che gli algoritmi di Deep Learning richiedono un intervento umano di gran lunga inferiore. Vediamo l’esempio del riconoscimento di un segnale stradale di stop da parte di una macchina Tesla. Se viene usato un algoritmo tradizionale di Machine Learning, un operatore (verosimilmente un ingegnere informatico) selezionerebbe manualmente le caratteristiche delle immagini, e le classificherebbe, verificherebbe l’output e modificherebbe l’algoritmo di conseguenza. Diversamente, un algoritmo di Deep Learning estrarrebbe automaticamente le caratteristiche del segnale di stop che ne permettono il riconoscimento, e imparerebbe dai propri errori.
Per funzionare bene, un algoritmo di Deep Learning richiede una grande quantità di dati.
Alcune funzioni dell’AI, come la computer vision o il Natural Language Processing, di cui parleremo nelle prossime lezioni, possono basarsi su tecniche di Intelligenza Artificiale semplice, o possono utilizzare Machine Learning tradizionale, Deep Learning o più di una tecnica insieme.
*Si ringrazia l’algoritmo di Natural Language Processing chatAI per aver collaborato alla stesura del testo colorato.